You’ll take my life, but I’ll take yours too
You’ll fire your musket, but I’ll run you through
So when you’re waiting for the next attack
You’d better stand, there’s no turning back
When I started Prowler almost eight years ago, I thought about calling it The Trooper (thetrooper as in the command line sounds good but I thought prowler was even better). I can say today, with no doubt that this version 4.0 of Prowler, The Trooper, is by far the software that I always wanted to release. Now, as a company, with a whole team dedicated to Prowler (Open Source and SaaS), this is even more exciting. With standard support for AWS, Azure, GCP and also Kubernetes, with all new features, this is the beginning of a new era where Open Cloud Security makes an step forward and we say: hey WE ARE HERE FOR REAL and when you’re waiting for the next attack, you’d better stand, there’s no turning back
Enjoy Prowler – The Trooooooooper! 🤘🏽🔥 song!

Breaking Changes
- Allowlist now is called Mutelist
- Deprecate the AWS flag
--sts-endpoint-regionsince we use AWS STS regional tokens. - The
--quietoption has been deprecated, now use the--statusflag to select the finding’s status you want to get fromPASS,FAILorMANUAL. - To send only FAILS to AWS Security Hub, now use either
--send-sh-only-failsor--security-hub --status FAIL - All
INFOfinding’s status has changedMANUAL.
We have deprecated some of our outputs formats:
- The HTML is replaced for the new Prowler Dashboard (
prowler dashboard) - The JSON is replaced for the JSON OCSF v1.1.0
New features to highlight in this version
Dashboard
- Prowler has local dashboard to play with gathered data easier. Run
prowler dashboardand enjoy overview data and compliance. 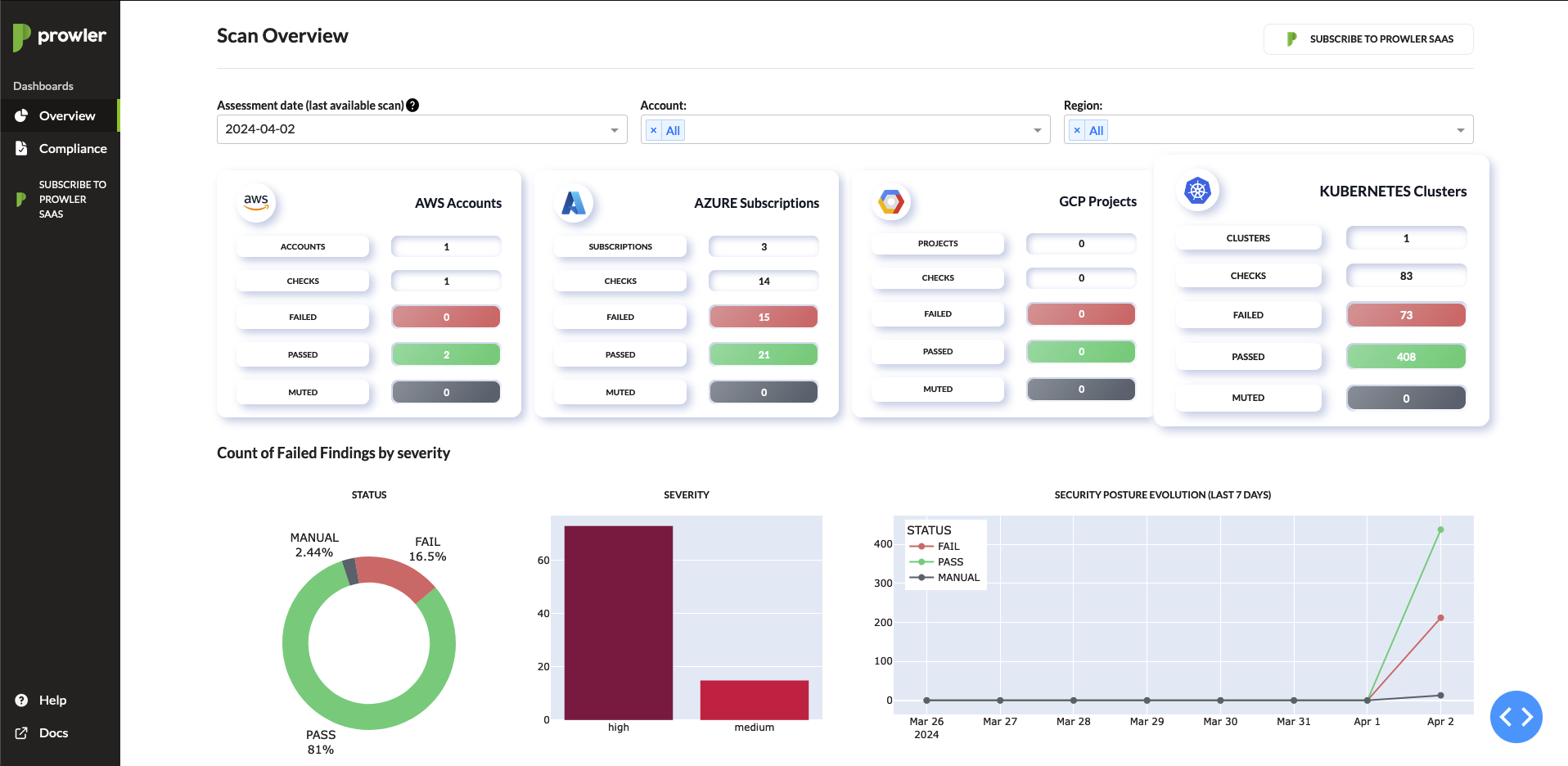
🎛️ New Kubernetes provider
- Prowler has a new Kubernetes provider to improve the security posture of your clusters! Try it now with
prowler kubernetes --kubeconfig-file <kube.yaml> - CIS Benchmark 1.8 for K8s is included.
📄 Compliance
- All compliance frameworks are executed by default and stored in a new location:
output/compliance
AWS
- The AWS provider execution by default does not scan unused services, you can enable it with
--scan-unused-services. - 2 new checks to detect possible threads, try it now with
prowler aws --category threat-detectionfor Enumeration and Privilege Escalation type of activities.
🗺️ Azure
- All Azure findings includes the location!
- CIS Benchmark for Azure 2.0 and 2.1 is included.
🔇 Mutelist
- The renamed mutelist feature is available for all the providers.
- In AWS a default allowlist is included in the execution.
🌐 Outputs
- Prowler now the outputs in a common format for all the providers.
- The only JSON output now follows the OCSF Schema v1.1.0
💻 Providers
- We have unified the way of including new providers for easier development and to add new ones.
🔨 Fixer
- We have included a new argument
--fixto allow you to remediate findings. You can list all the available fixers withprowler aws --list-fixers