Today we are releasing a new major version of Prowler 🎉🥳🎊🍾, the Version 3 aka Piece of Mind.
Take Prowler v3 as our 🎄Christmas gift 🎁 for the Cloud Security Community.

Artwork property of Iron Maiden
Piece of Mind was the fourth studio album of Iron Maiden. Its meaning fits perfectly with what we do with Prowler in both senses: being protected and at the same time, this is the software I would have wanted to write when I started Prowler back in 2016 (this is now, more than ever, a piece of my mind). Now this has been possible thanks to my awesome team at Verica.
No doubt that 2022 has been a pretty interesting year for us, we launched ProwlerPro and released many minor versions of Prowler. Now enjoy Sun and Steel while you keep reading these release notes.
If you are an Iron Maiden fan as I am, you have noticed the latest minor release of Prowler (2.12) was a song from this very same album, just a clue of what was coming! In Piece of Mind you can find one of the most popular heavy metal songs of all times, The Trooper, which will be a Prowler version to be released during 2023.
Prowler v3 is more than a new version of Prowler, it is a whole new piece of software, we have fully rewritten it in Python and we have made it multi-cloud adding Azure as our second supported Cloud Provider. Prowler v3 is also way faster, being able to scan an entire AWS account across all regions 37 times faster than before, yes! you read it correctly, what before took hours now it takes literally few minutes or even seconds.
New documentation site:
We are also releasing today our brand new documentation site for Prowler at https://docs.prowler.cloud and it is also stored in the docs folder in the repo.
What’s Changed:
Here is a list of the most important changes in Prowler v3:
- 🐍 Python: we got rid of all bash and it is now all in Python.
pip install prowlerthen runprowlerthat’s all. - 🚀 Faster: huge performance improvements.
Scanning the same account takes from 2.5 hours to 4 minutes. - 💻 Developers and Community: we have made it easier to contribute with new checks and new compliance frameworks. We also included unit tests and native logging features. And now the CLI supports long arguments and options.
- ☁️ Multi-cloud: in addition to AWS, we have added Azure.
- ✅ Checks and Groups: all checks are now more comprehensive and we provide resolution actions in most of them. Their ID is no longer tight to CIS but they are self-explanatory. Groups now are dynamically generated based on checks metadata like services, categories, severity and more).
- ⚖️ Compliance: we are including full support for CIS 1.4, CIS 1.5 and the new Spanish ENS in this release, more to come soon! Compliance also has its own output file with their own metadata and to create your own is easier than ever before making more comprehensive reports.
- 🧩 Compatibility with v2: most of the options are the same in this version in order to support backward compatibility however some options like assume role or AWS Organizations query are now different and easier to use.
- 🔄 Consolidated output formats: now both CSV and JSON reports come with the same attributes and compared to v2, they come with more than 40 values per finding. HTML, CSV and JSON are created every time you run
prowler. - 📊 Quick Inventory: introduced in v2, we have fine tuned the Quick Inventory feature and now you can get a list of all resources in your AWS accounts within seconds.
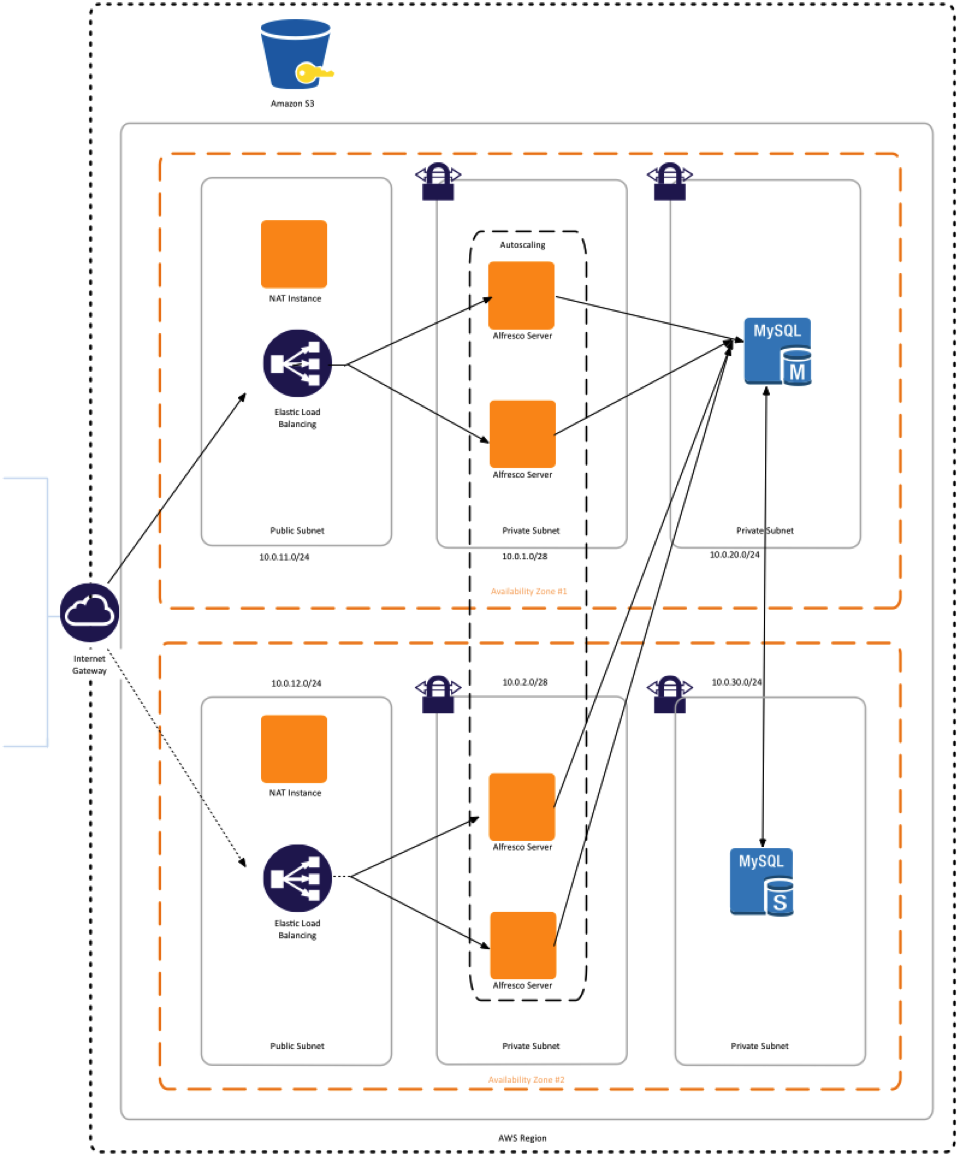
Prowler new default overview:
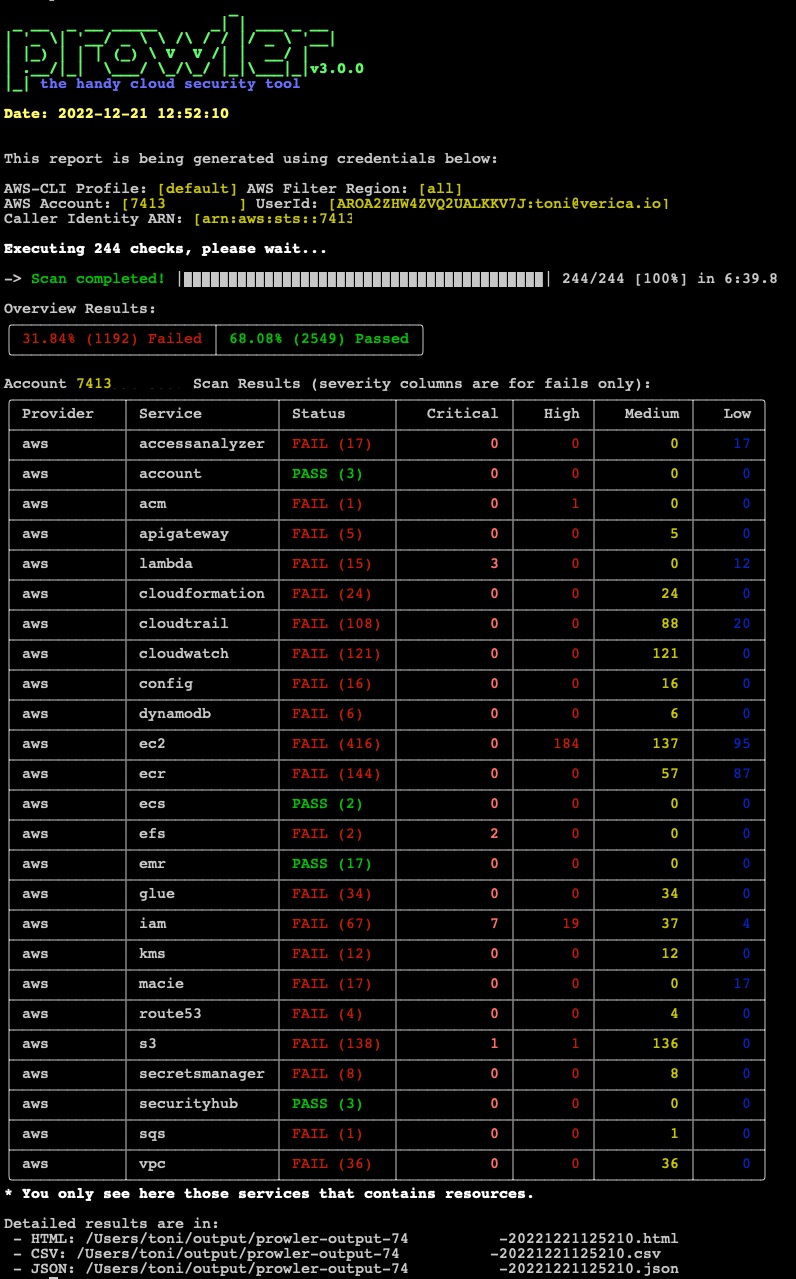
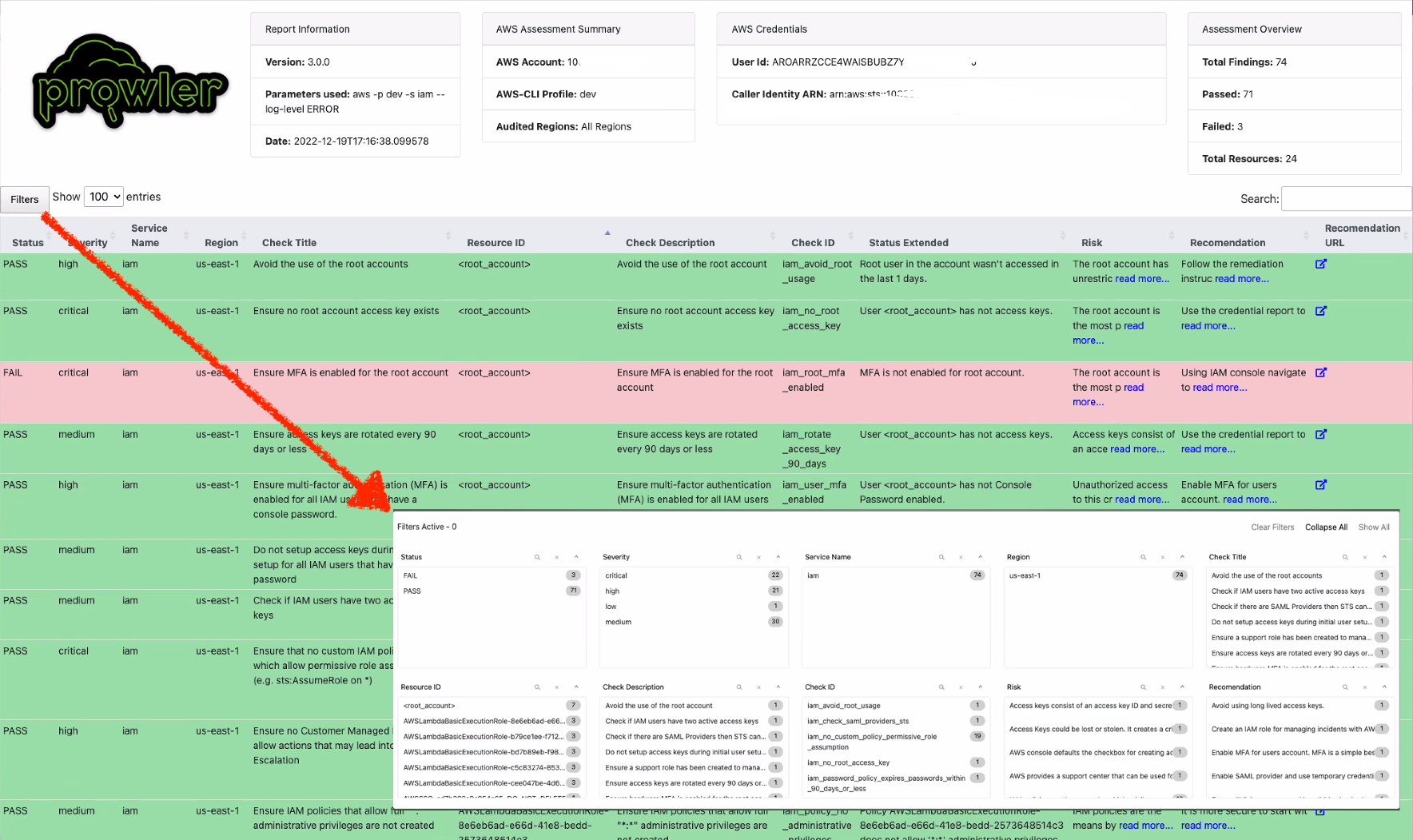
Prowler updated HTML report:
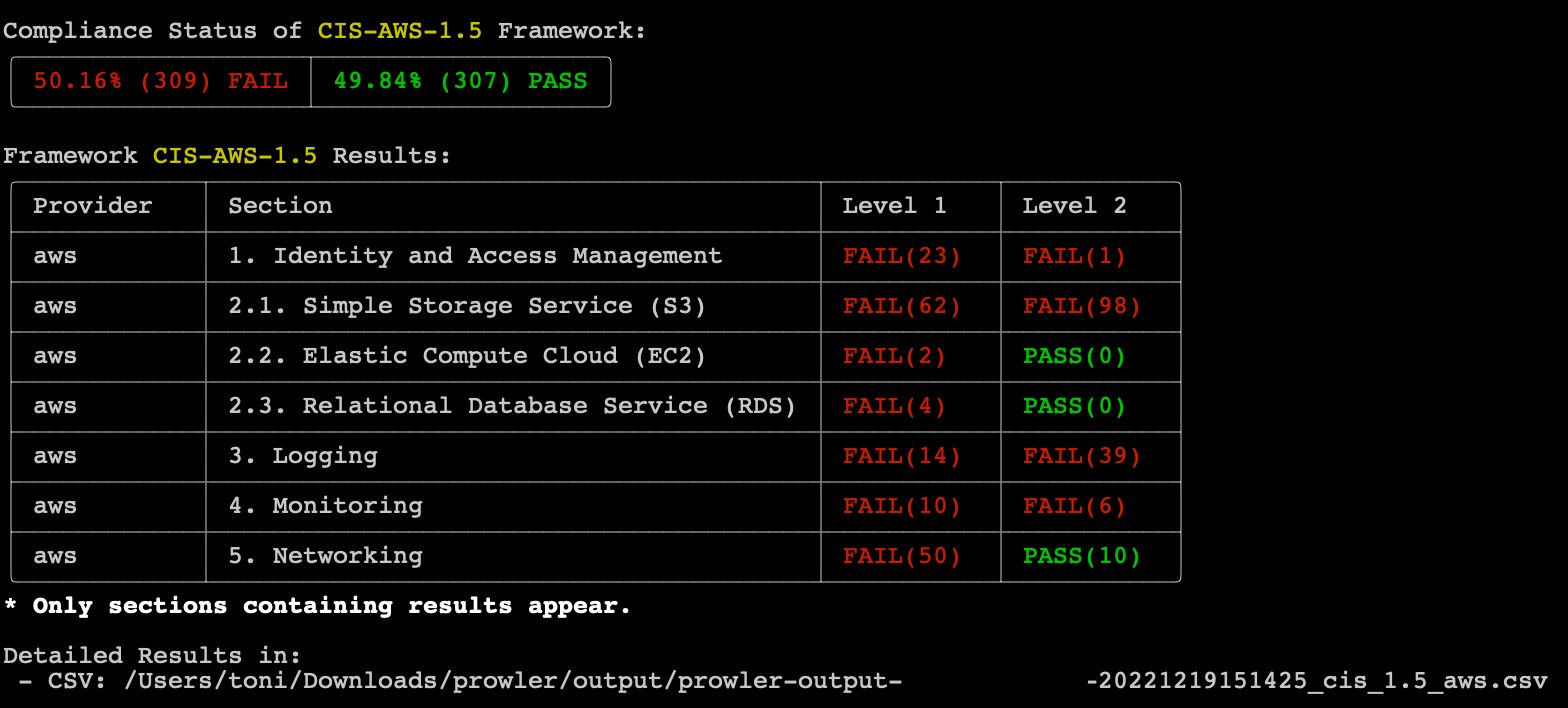
Prowler compliance overview:
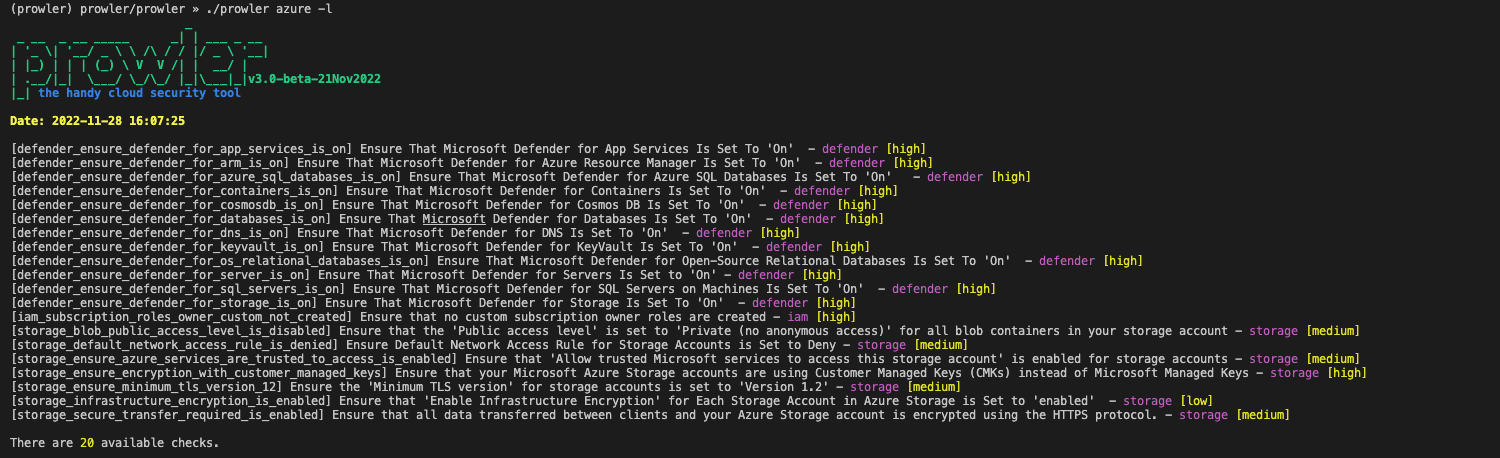
Prowler list of Azure checks:
What is coming next?
- More Cloud Providers and more checks: in addition to keep adding new checks to AWS and Azure, we plan to include GCP and OCI soon, let us know if you want to contribute!
- XML-JUNIT support: we didn’t add that to v3, if you miss it, let us know in https://github.com/prowler-cloud/prowler/discussions
- Compliance: we will add more compliance frameworks to have as many as in Prowler v2, we appreciate help though!
- Tags based audit: you will be able to scan only those resources with specific tags.





 In order to give back to the Open Source community what we take from it (actually from the
In order to give back to the Open Source community what we take from it (actually from the  Now, with this provided CloudFormation template you can deploy SecurityMonkey pretty much production ready in a couple of minutes.
Now, with this provided CloudFormation template you can deploy SecurityMonkey pretty much production ready in a couple of minutes.