 If you work with AWS, you may have to perform a forensics analisys at some point. As discussed in previous articles here, there are many tasks we can achieve in the cloud.
If you work with AWS, you may have to perform a forensics analisys at some point. As discussed in previous articles here, there are many tasks we can achieve in the cloud.Here is a quick quide based on AWS-CLI on how to install, upload and use the well known CAINE7 distribution up in the Amazon Cloud importing it as an EC2 AMI:
- First of all start CAINE7.iso as live CD in Virtualbox, 12GB of disk in VHD format will be fine ( if you don’t use VHD or you have VMDK instead you can convert it with “VBoxManage clonemedium CAINE7.vmdk CAINE7.vhd –format vhd”)
- Inside CAINE:
- Run BlockON/OFF app from Desktop icon, select your virtual hard drive and make it Writable.
- Go to Menu / System / Administration / gParted
- In gParted Device / Create Partition Table… msdos
- Partition new create a 10GB partition and leave the rest empty
- Create another partition linux-swap for the remaining 2GB
- Edit – Apply all operations
- Run Systemback (installer) form the Desktop icon.
- System Install, fill the form with user full name: caine, system user: ec2-user, your password and hostname: caine. Then Next
- Select the 10GB partition and set the mount point /
- Click Next and the installation will start
- Once the installation is finished you can stop the virtual machine, remove the liveCD, start it and log in to the VM again to do some additional steps inside your just installed CAINE7.
- Update and upgrade:
- sudo apt-get update; sudo apt-get upgrade
- Install aws-cli:
- sudo pip install aws-cli
- Now we will install some dependences needed to get access via RDP once we run CAINE in AWS, just like if it is in our local workstation.
- sudo apt-get install xrdp curl
- sudo sed -i s/port=-1/port=ask-1/g /etc/xrdp/xrdp.ini
- sudo sed -i s#/\.\ \/etc\/X11\/Xsession#mate-session#g /etc/xrdp/startwm.sh
- sudo service xrdp restart
- Extra: install the Amazon EC2 Simple Systems Manager (SSM) agent to process Run Command requests remotely and automated:
- cd /tmp
- curl https://amazon-ssm-<region>.s3.amazonaws.com/latest/debian_386/amazon-ssm-agent.deb -o amazon-ssm-agent.deb
- dpkg -i amazon-ssm-agent.deb
- Now we have to upload this VM VHD file to a S3 bucket, it will be around 8GB

- aws s3 cp CAINE7.vhd s3://your-forensics-tools-bucket/CAINE7.vhd
- This will take time, depending on your bandwith.
- If the AWS IAM user you are running doesn’t have proper permissions, you should review and follow these prerequisites http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/VMImportPrerequisites.html
- Then we can import this virtual hard drive as AWS AMI. Firs create a json file like below to use it as parameter for the import task (caine7vm.json):
[{
“Description”: “CAINE7”,
“Format”: “vhd”,
“UserBucket”: {
“S3Bucket”: “your-forensics-tools-bucket”,
“S3Key”: “CAINE7.vhd”
}
}]
- Lets perform the import:
- aws ec2 import-image –description “CAINE7” –disk-containers file://caine7vm.json –profile default –region us-east-1
- NOTE: you probably don’t need to specify profile or region.
- The import taks may take some minutes, depending on how big is the VHD and how busy is AWS by that time. To check the status use this command:
- aws ec2 describe-import-image-tasks –profile default –region us-east-1 –query ‘ImportImageTasks[].[ImportTaskId,StatusMessage,Progress]’
- or this one with your custom “import-ami-XXXXX”
- aws ec2 describe-import-image-tasks –profile default –region us-east-1 –query ‘ImportImageTasks[].[ImportTaskId,StatusMessage,Progress]’ –cli-input-json “{ \”ImportTaskIds\”: [\”import-ami-XXXXX\”]}”
- You will see “StatusMessage”: “pending” –> “validated”–> “converting” –> “preparing to boot” –> “booted” –> “preparing ami” –> “completed”
- Once it is completed, look for your brand new AMI id:
- aws ec2 describe-images –owners self –profile default –region us-east-1 –filters “Name=name,Values=import-ami-XXXXX”
- Good, we know the AMI id so let’s create a new instance inside an existing VPC and a Public Subnet (I use t2.medium with 2GB of RAM), please use your own Security Group with RDP and SSH open and your own ssh keyname:
- aws ec2 run-instances –image-id ami-XXXX –count 1 –instance-type t2.medium –key-name YOURKEY –security-group-ids sg-YOURSG –subnet-id subnet-YOURPUBLIC –profile default –region us-east-1
- Add it a tag for better identification:
- aws ec2 create-tags –resources i-XXXX –tags Key=Name,Value=Investigator –profile default –region us-east-1
- At this point you can attache a public IP to the instance and get access to it.
- First allocate a public Elastic IP:
- aws ec2 allocate-address –domain vpc-XXXX –profile default –region us-east-1
- Then associate that new Elastic IP to our just launched CAINE7 instance (changeeipalloc-XXXX):
- aws ec2 associate-address –instance-id i-XXXX –allocation-id eipalloc-XXXX –profile security –region us-east-1
- Now open your favorite remote desktop application and access to your CAINE7, remember you will be asked for the username and password you set when CAINE was installed in your VirtualBox VM:
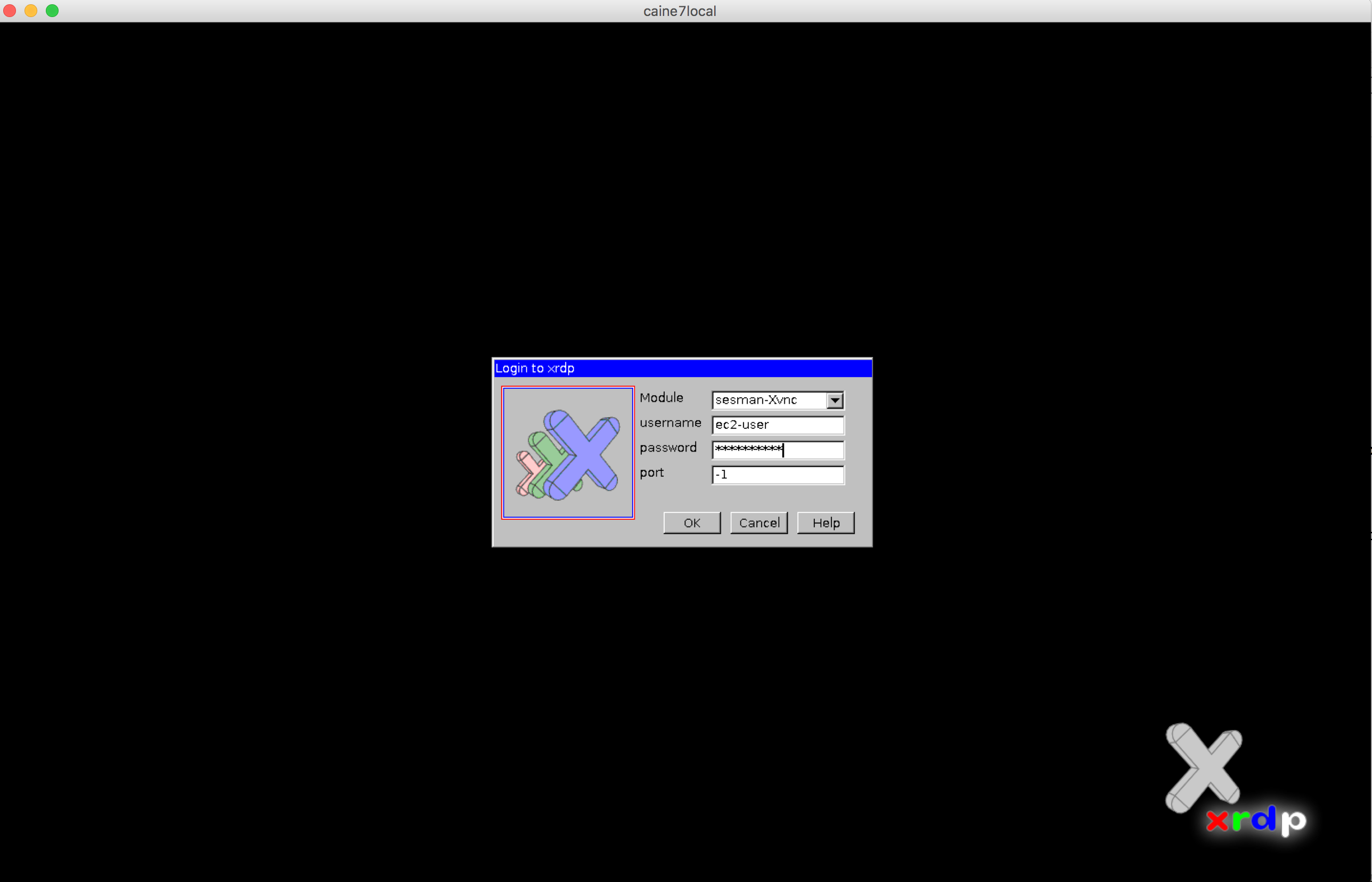
- Now you should be in!

- To attach another volume and start your investigation just take a look to my previous introductory post on AWS forensics.

