As part of the work I’m doing for the upcoming Alfresco Summit, where I will be talking about my favorite topic: “Security and Alfresco”, I have written a few lines about Alfresco node deletion, how it works and why is important to take it into account in terms of security control.
I just wanted to clarify how Alfresco works when a content item is deleted and also how content deletion works in Records Management (RM). Basic content deletion is already very well explained in this Ixxus blog post but there are some differences in the database schema between Alfresco 4.1 and 4.2 worth noting, such as the alf_node table has a field named ‘node_deleted’ in versions 4.0 and earlier.
To develop a deep knowledge about Alfresco security and also how to configure Alfresco backup and disaster recovery, you should first need to understand how the Alfresco repository manages the lifecycle of a content item.
Node creation:
When a node is created,regardless how it is uploaded or created in Alfresco (via the API, web UI, FTP, CIFS, etc.)Alfresco will do the following:
- Metadata properties are stored into the Database in the logical store workspace://SpacesStore (alf_node, alf_content_url among others).
- The file itself is store and renamed as .bin under alf_data/contentstore/YYYY/MM/DD/hh/mm/url-id-of-the-file.bin
- Next, depending on your indexing you chose, its index entries are created within Lucene (alf_data/lucene-indexes/workspace/SpacesStore) or Solr (alf_data/solr/workspace/SpacesStore).
- Finally, in most cases, a content thumbnail is created as a child of the file created.
Node deletion:
There are two phases to node deletion:
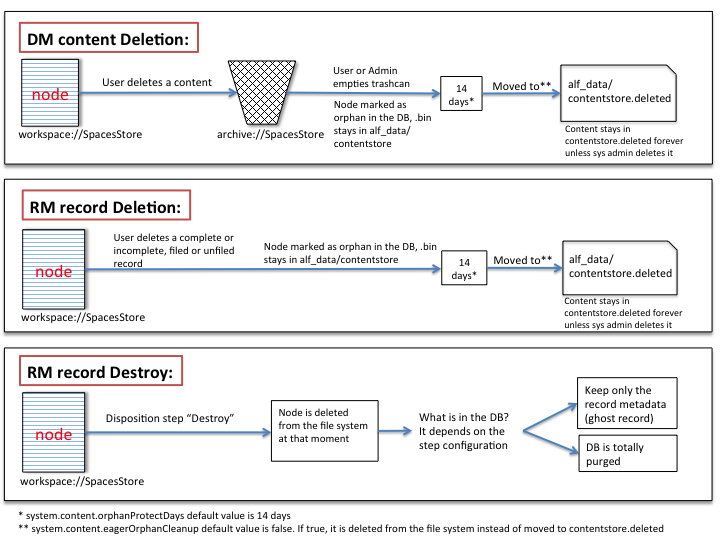
Phase 1- A user or admin deletes a content item (sending it to the trashcan):
- When someone deletes a content item, the content and its children (eg. thumbnails) are moved (archived) within the DB from workspace://SpacesStore to archive://SpacesStore. Nothing else happens in the DB.
- The actual content “.bin” file remains in the same location inside the contentstore directory.
- Finally,the indexes are moved from the existing location to the corresponding archive alf_data/lucene-indexes/archive/SpacesStore) or Solr (alf_data/solr/archive/SpacesStore) depending on your index engine selection.
NOTE: A deleted node stays in the trashcan FOREVER, unless the user or admin either empties the trashcan or recovers the file. This default” behavior can be changed by using third party modules that empty the trashcan automatically on a custom schedule. See below for more information on these modules.
The trashcan may be found at these locations:
Alfresco Share: User -> My Profile -> Trashcan (admin user will see all users deleted files, since 4.2 all users can also see and restore their own deleted files).
Alfresco Explorer: User Profile -> Manage Deleted Items (for all users).
Phase 2- Any user or admin (or trashcan cleaner) empties the trashcan:
That means the content is marked as an “orphan” and after a pre-determined amount of time elapses, the orphaned content item ris moved from the alf_data/contentstore directory to alf_data/contentstore.deleted directory.
Internally at DB level a timestamp (unix format) is added to alf_content_url.orphan_time field where an internal process called contentStoreCleanerJobDetail will check how many long the content has been orphaned.,f it is more than 14 days old, (system.content.orphanProtectDays option) .bin file is moved to contentstore.deleted. Finally, another process will purge all of its references in the database by running nodeServiceCleanupJobDetail and once the index knows the node has bean removed, the indexes will be purged as well.
NOTE: Alfresco will never delete content in alf_data/contentstore.deleted folder. It has to be deleted manually or by a scheduled job configured by the system administrator.
By default, the contentStoreCleanerJobDetail runs every day at 4AM by checking how the age of an orphan node and if it exceeds system.content.orphanProtectDays (14 days) it is moved to contentstore.deleted.
Additionally, the nodeServiceCleanupJobDetail runs every day at 9PM and purges information related to deleted nodes from the database.
Now, that we understand how Alfresco works by default, let’s learn how to modify Alfresco’s behavior in order to clean the trashcan automatically:
There are several third party modules to achieve this, but I recommend the Alfresco Trashcan Cleaner by Alfresco’s very own Rui Fernandes. Tt can be found at https://code.google.com/p/alfresco-trashcan-cleaner/.
Once the amp is installed, you can use this sample configuration by copying it to alfresco-global.properties:
[bash]
trashcan.cron=0 30 * * * ?
trashcan.daysToKeep=7
trashcan.deleteBatchCount=1000
[/bash]
The options above configure the cleaner to run every hour at thethe half hour and it will remove content from the trashcan and mark them as orphan if a content has been in the trashcan for more than 7 days. It will do this in batches of 1000 deletions every time it runs. To delete from the trashcan without waiting any grace period set the trashcan.daysToKeep property value to -1.
Can I configure Alfresco to avoid using contentstore.deleted and ensure it really deletes a file after the trashcan is cleaned?
Yes, this is possible by setting system.content.eagerOrphanCleanup=true in alfresco-global.properties and once the trashcan is emptied, the file will not be moved to contentstore.deleted but it will be deleted from the file system (contentstore). After that, nodeServiceCleanupJobDetail will purge any related information from the database. Using sys:temporary aspect it also perform same behavior.
So, what is the recommended configuration for a production server?
This is something you have to figure out based on your backup and disaster recovery strategy. See my Alfresco Summit presentation and white paper here: http://blyx.com/2013/12/04/my-talk-about-alfresco-backup-and-recovery-tool-in-the-alfresco-summit/.
If you have a proper l backup strategy, you can offer your users a grace period of 30 days to recover their own deleted documents from the trashcan and after the grace period delete them simultaneously from the trashcan and the filesystem. This can be achieved by installing the previously mentioned trashcan-cleaner and with this configuration in alfresco-global.properties:
[bash]
system.content.eagerOrphanCleanup=true
trashcan.cron=0 30 * * * ?
trashcan.daysToKeep=30
trashcan.deleteBatchCount=1000
[/bash]
And what about Alfresco Records Management, does it work in the same way? How a record destruction works?
In the Records Management world you don’t tend to delete documents as often it is done in Document Management. When a content item is deleted from the RM file plan, it is considered to be a regular delete operation. This is rarely used and only done by RM admins when there is some justifiable reason such as correcting a mistake that requires a record to be removed.
The only difference is that the deleted record by-passes the archive store, hence it never goes to the trashcan, it is marked as orphan once it is deleted. Then it will be moved to contentstore.deleted after orphanProtectDays or it is truly deleted if eagerOrphanCleanup is set as true.
Destruction of a record works in the same way that a record is removed, this will by-pass the archive and immediately trigger the clean-up (eagerOrphanCleanup) process so the content does not stay in the file system contentstore or contentstore.deleted.
As far as the meta-data goes, there are two options; the first is that all the meta-data (and hence the node itself) are completely deleted, the alternative method cleans out all the content but the node remains with only the meta-data (called ghosting). In Alfresco RM versions before 2.2 this was a global configuration value (rm.ghosting.enabled=true), in 2.2 it can be defined on the destroy step of the disposition schedule: “Maintain record metadata after destroy”.
Some final words on content deletion:
As we have seen, Alfresco offers different ways to delete content. It is important to remember, even if Alfresco completely deletes content such as when using the destroy option in RM or by using eagerOrphanCleanup, Alfresco will not wipe the removed content from the physical storage, it therefore can be recovered by file system recovery tools. Wiping a deleted content item may vary depending on multiple factors, since filesystem type to hardware configuration, etc. If you want to guarranty a real physical wipe of a file in your file system, a third party software must be used to “zero out” the corresponding disk sectors. The specific tools depend on the operating system type, hardware, etc.
Thanks to my colleagues at Alfresco Kevin Dorr, Roy Wetherall for the Records Management section and Luis Sala for the document syntax review.
